
python:正则表达式
范例一:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result=re.match('^Hello\s(\d+)\sWorld',content)
print(result)
print(result.group())
print(result.group(1))
print(result.span())
关键知识点:
re.match(pattern, string):从字符串开头开始匹配正则表达式,若开头不匹配则返回None,匹配成功则返回Match对象。- 正则表达式符号:
^:匹配字符串开头(re.match本身已从开头匹配,此处可省略,但写出来更明确)。\s:匹配任意空白字符(空格、制表符等)。\d+:匹配 1 个或多个数字。():分组匹配,将括号内的内容作为一个分组,可通过group(n)提取。
- Match 对象的方法:
group():返回整个匹配的字符串(等同于group(0))。group(1):返回第一个分组匹配的内容(若有多个分组,可依次用group(2)、group(3)提取)。span():返回匹配的起始和结束索引(元组形式)。
范例二:
import re
content = 'Hello 1234567 World_This is a Regex Demo'
result=re.match('^Hello.*Demo$',content)
print(result)
print(result.group())
print(result.span())
关键知识点:
1. 正则表达式模式
^Hello.*Demo$ 的含义:
^:匹配字符串的开头Hello:匹配字面量字符串 "Hello".*:*表示匹配前面的字符(.代表任意字符,除换行符)0 次或多次Demo$:$匹配字符串的结尾,这里匹配字面量 "Demo"
范例三:
import re
s = "Python is good, Python is powerful"
# 正则:匹配以Python开头,以is结尾的内容(非贪婪匹配)
pattern_lazy = r"Python.*?is"
result_lazy = re.search(pattern_lazy, s)
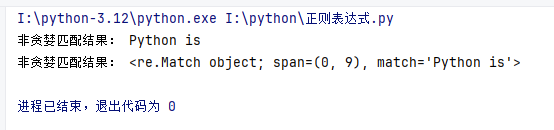
print("非贪婪匹配结果:", result_lazy.group())
print("非贪婪匹配结果:", result_lazy)
import re
s = "Python insert is good, Python is powerful"
# 正则:匹配以Python开头,以is结尾的内容(非贪婪匹配)
pattern_lazy = r"Python.*?is"
result_lazy = re.search(pattern_lazy, s)
print("非贪婪匹配结果:", result_lazy.group())
print("非贪婪匹配结果:", result_lazy)
在python 和is 之间增加了insert,结果如下:

import re
s = "Python insert is good, Python is powerful"
# 正则:匹配以Python开头,以is结尾的内容(非贪婪匹配)
pattern_lazy = r"Python.*is"
result_lazy = re.search(pattern_lazy, s)
print("非贪婪匹配结果:", result_lazy.group())
print("非贪婪匹配结果:", result_lazy)
将.*?更改为.*之后,运行结果如下:

.*正则表达式将所有可能的符合正则要求的范围全部包含了进来 !